
Alaska Lake and Pond Occurrence Dataset
The Alaska Lake and Pond Occurrence Dataset is available for download here: https://doi.org/10.3334/ORNLDAAC/2399
Motivation and dataset characteristics
ALPOD provides a spatially explicit representation of the location and variability of over 1 million water bodies. Here is a visual introduction to the characteristics of the dataset:

Maps of ALPOD lakes. Panels (a-d) show ALPOD lake statistics calculated for HUC12 watersheds from the National Hydrography Dataset: (a) lake fraction (percentage of watershed covered by open water at least 25% of the study period), (b) average lake size within each watershed, (c) lake density calculated as the number of lakes per 100 km2, and (d) total shoreline distance (i.e., lake perimeter). Panel (e) shows the open water occurrence image for individual lakes ranging from 0.005 km2 to 66.24 km2, which shows relationship between open water occurrence and lake polygons, and (f) displays a detailed example of the vector products derived from the occurrence image within the Little Black River floodplain near the Yukon Flats.
Improvements to the spatiotemporal resolution of satellite imagery in recent years have enabled researchers to document seasonal fluctuations in Arctic-Boreal waterbody extent. Their results demonstrate that the size, number, and total area of lakes and ponds can vary significantly over daily timescales, which limits the utility of static or snapshot-based surface water datasets for accurately characterizing the surface water distribution in high-northern latitudes. To overcome this limitation, we produced a lake and pond open-water occurrence map using every available Sentinel-2 image during the ice-free months of 2016-2021. This lake and pond occurrence raster is a singleband, 10 m resolution GeoTIFF covering all of Alaska with pixel values recording the percentage of observationsin which that location was identified as open water belonging to a lake or pond. We also produced vector-based lake products derived from the occurrence map at multiple occurrence thresholds. This lake dataset accounts for six years of dynamic seasonality and is thus more robust against the effects of degraded individual image quality due to clouds, cloud shadows, or haze. Our aim was to produce a dataset that has utility for understanding lake and pond dynamics at scales ranging from single water bodies to the entire state of Alaska.
More examples of the ALPOD vector product over local to regional scales:
| ALPOD at local scales | ALPOD at a regional scale |
|---|---|
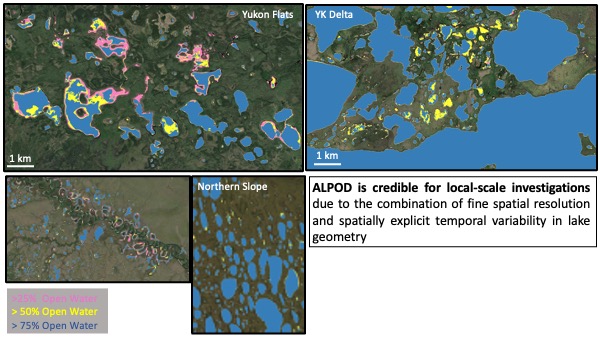 | 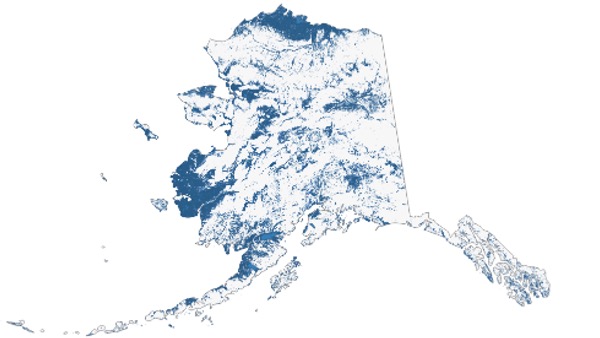 |
Dataset Engineering
Our datset construction methodology combines object and pixel-based water classification methods. Deep-learning semantic segmentation models such as U-Nets are useful for mapping lakes and ponds because they can separate these water bodies from features of the landscape – such as rivers, cloud shadows, hillshades, and burn scars – that have similar reflectance properties as lakes. However, these models are computationally expensive and are not currently compatible with Google Earth Engine, thus limiting their applicability for occurrence mapping over a large study area. NDWI historam thresholding is a pixel-based method for mapping open water, and its computational efficiency promotes the utility of NDWI thresholding altorithms for mapping surface water over large extents and at high frequencies. Our approach overcomes the relative disadvantages of both the object and pixel-based classification methods by first using a U-Net lake identification model to produce a maximum possible lake extent mask across our study site. This mask filters out the extraneous features of the landscape listed aboe and serves as the ‘region of interest’ for an adaptive NDWI thresholding algorithm, which is a binary water classifier applied to every available Sentinel-2 image in GEE. The ALPOD lake occurrence raster is a singleband composite built from each of these open-water classifications.
The methodological approach to constructing the ALPOD dataset is as follows:
Here is the dataset construction progression from U-Net predictions, manual edits to produce the maxium possible lake extent mask, the Google Earth Engine outputs, and the cleaned lake occurrence raster using watershed segmentation.
